
Het logisch data warehouse (LDW) is de data architectuur van de toekomst. Flexibel, snel en uitermate geschikt om self service BI te ondersteunen. Ik heb het afgelopen jaar al veel gepubliceerd over de architectuur en voordelen hiervan.
In een tijd waarin de rol van informatie steeds bedrijfskritischer is geworden en data-analyse een onderscheidende rol speelt in primaire bedrijfsprocessen, is de roep om een architectuur die informatie sneller en flexibeler kan leveren enorm toegenomen. Niet zo gek als je weet dat het ontbreken van de juiste informatie complete bedrijfsprocessen of zelfs bedrijven kan stilleggen. Informatie is de brandstof van de 21e eeuw geworden en dat vraagt om een nieuwe motor!
Hybride architectuur
Maar wat dan met de investeringen die we gedaan hebben in traditionele data warehouses, data marts, analyses, rapportages en dashboards? Allemaal weggegooid geld? Moeten we alles dan opnieuw opbouwen? Nee, zeker niet! Ik adviseer om voor een hybride aanpak met datavirtualisatie te kiezen. Hier leg ik graag uit hoe je op een beheersbare manier kunt migreren naar zo’n hybride architectuur zonder dat je de informatiewinkel hoeft te sluiten. Een overzichtelijke en stapsgewijze ‘agile‘ migratie met zoveel mogelijk behoud van gedane investeringen en minimalisering van risico’s. Daar is de architectuur van het logisch data warehouse namelijk uitermate geschikt voor!
Datavirtualisatie
Eén van de manieren waarop het logisch data warehouse kan worden geïmplementeerd, is met behulp van het concept datavirtualisatie. Er bestaan diverse datavirtualisatie platformen. Bij Axians werken we vooral met , een zeer compleet datavirtualisatie platform dat functionaliteit biedt van ontkoppeling van bronsystemen tot en met het publiceren van informatie voor BI tools en allerlei mogelijke informatieservices. De basis voor onze migratieaanpak is een ‘ontkoppeling’ met behulp van virtuele data marts, maar voordat we de diepte ingaan, eerst nog even een overzicht van de architectuur van het logisch data warehouse op basis van datavirtualisatie:
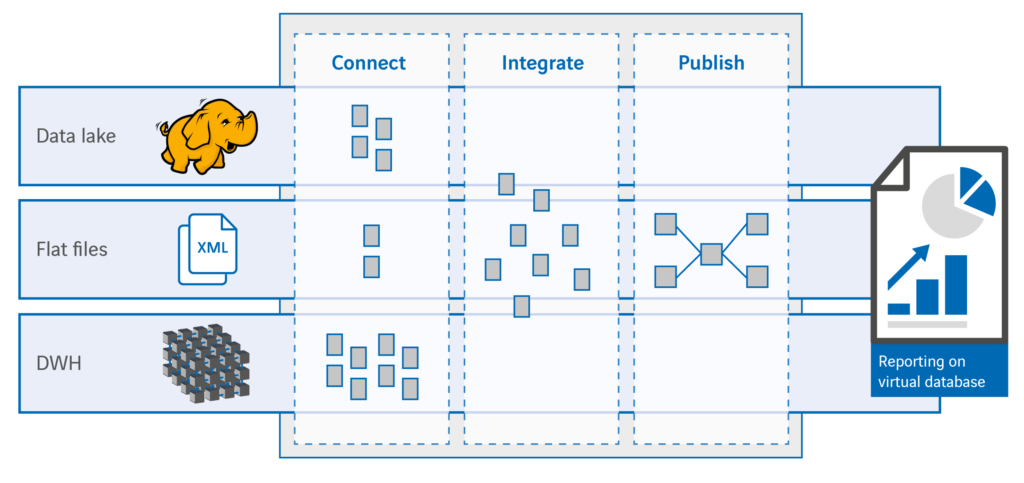
De connect laag zorgt voor de ontkoppeling van de databronnen. Deze laag verzorgt de toegang tot de benodigde data in de aangesloten bronsystemen. De combine laag maakt herbruikbare, geïntegreerde elementen van de data en de publish laag is het uniforme informatiemodel (met daarin alle business logica) waar applicaties en services gebruik van maken. De uniforme informatie in de publish laag kan op diverse manieren ter beschikking worden gesteld: virtual database, view, webservice, QVD etc.
Aanpak migratie
Tijdens de migratie naar een logisch data warehouse moet de informatiewinkel uiteraard open blijven. Onder geen beding mogen informatieleveringen in gevaar komen, maar we willen vooral de mogelijkheid creëren om nieuwe data- en informatiestromen toe te voegen buiten de traditionele, reguliere architectuur van het klassieke data warehouse om. Een extra reden om de migratie in kleine beheersbare stappen te doen, is dat bestaande informatiestromen geen gevaar lopen. Stapsgewijs naar een hybride architectuur, terwijl de winkel gewoon open blijft en klanten tevreden zijn.
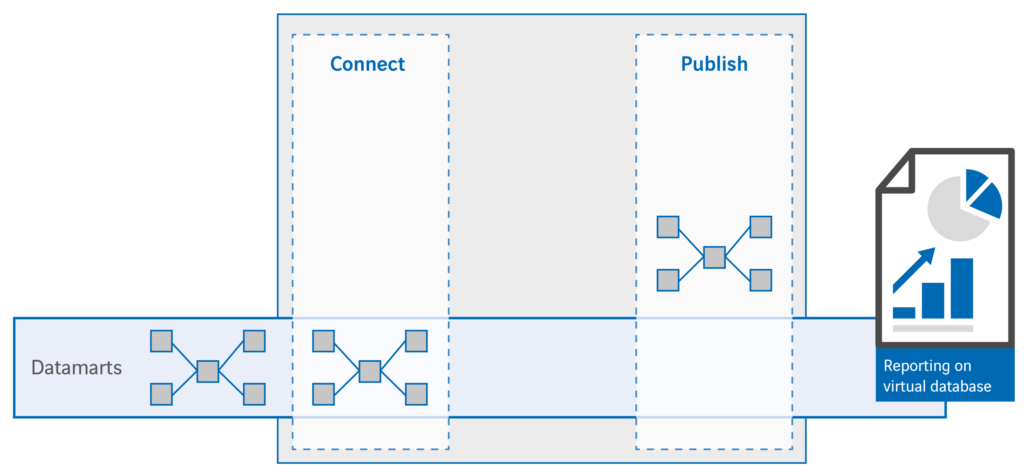
Stap 1: virtuele datamarts
De eerste stap in de migratie is de virtualisatie van bestaande informatiebronnen, vaak data marts. Door in de publish laag virtuele tabellen op te nemen die direct verwijzen naar de fysieke data mart tabellen worden die losgekoppeld van waar de data zich bevindt. Hiermee worden het eigenlijk ‘virtuele data marts’.
Stap 2: informatie services migreren
Nu passen we bestaande informatieservices, zoals rapporten en dashboards, aan zodat ze hun gegevens op gaan halen uit de virtuele data marts. Meestal is dit alleen maar een kwestie van het omzetten van een connectie van de fysieke database naar de virtuele database. Zo hebben we onze informatieservices aangesloten op een eerste versie van ons logisch data warehouse! Door de ontkoppeling van de logica en de fysieke gegevensopslag hebben we een van de belangrijkste kenmerken van het logisch data warehouse gerealiseerd.
Waar het logisch data warehouse vooral om draait is het ‘informatieproduct’ zo slim mogelijk aan te bieden aan de afnemer, zonder dat die geconfronteerd wordt met de complexiteit van de onderliggende architectuur. Vergelijk het met een restaurant; afhankelijk van wat de klant wil eten krijgt hij het eten snel en naar wens opgediend zonder dat hij in de keuken hoeft te gaan kijken. Vegetarisch? Glutenallergie? Geen melkproducten? Geen probleem, dat leveren we allemaal vanuit dezelfde keuken! De behoefte staat ineens voorop. Het moment, de vorm, de smaak en de presentatie zijn bepalend, niet het proces!
Stap 3: nieuwe bronnen toevoegen
Na de eerste twee migratiestappen hebben we al een groot deel van de migratie voltooid: logica en bronsystemen zijn ontkoppeld. We hebben nu ‘vrijheid van input’ en ‘vrijheid van output’: we kunnen databronnen toevoegen zonder de vaste route van het klassieke data warehouse te volgen (ETL, replicatie etc.) en de informatie eenvoudig, op verschillende manieren publiceren. Als we nieuwe data willen toevoegen wordt de nieuwe gegevensbron bekend gemaakt in de connect laag. Via de publish laag worden de nieuwe gegevens vervolgens beschikbaar gesteld aan gebruikers. Het resultaat is een logisch data warehouse dat de virtuele data mart uit stap 1 bevat en ‘parallel’ de nieuwe informatie, zonder dat deze twee met elkaar geïntegreerd zijn. Nu kunnen we ook nieuwe gebruikers – REST API’s, SOAP web services en BI tools – aansluiten en rechten geven op specifieke informatie uit het logisch data warehouse met behulp van Denodo.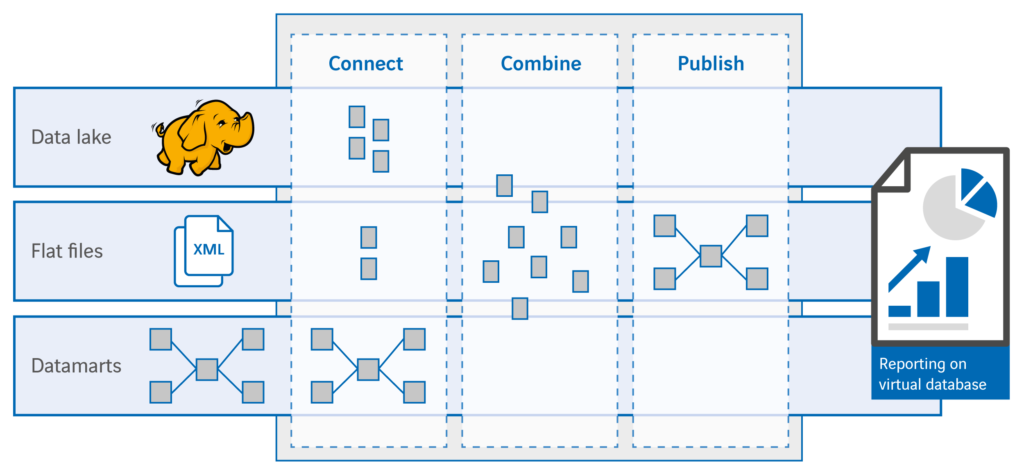
Stap 4: integratie
De basis van het logisch data warehouse staat nu. De kans is groot dat we de behoefte krijgen om nieuwe informatie te integreren met data uit het klassieke data warehouse. De stap die we dan moeten zetten is dat we de benodigde delen uit het data warehouse en de nieuwe informatie toevoegen aan de combine laag. Hier leggen we vast hoe de data gekoppeld wordt en hoe de hieruit resulterende dataset eruit komt te zien. De nieuwe entiteiten uit de combine laag kunnen nu toegevoegd worden aan de bestaande data marts in de publish laag. Het resultaat is een virtuele data mart die data ontsluit uit zowel het klassieke data warehouse als uit nieuwe databronnen.
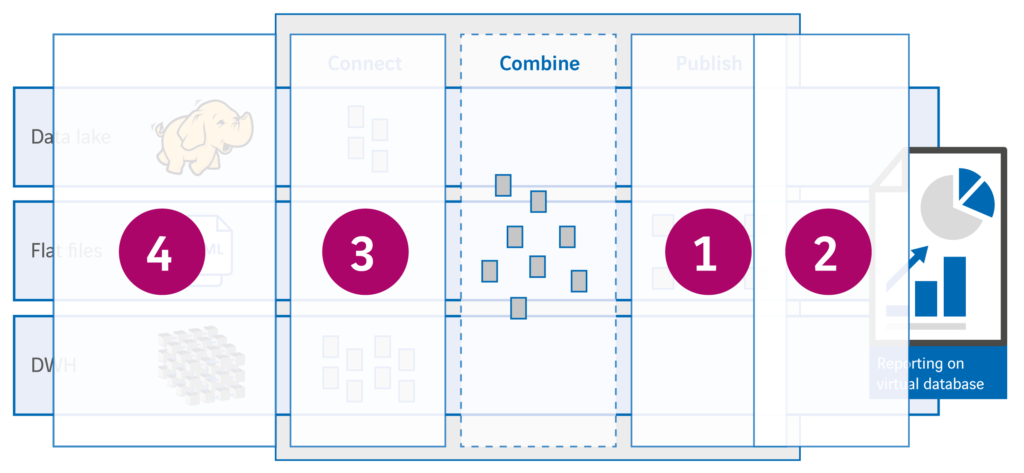
Vierstaps model
We kunnen dus in beheersbare en overzichtelijke stappen migreren naar een logisch data warehouse, zonder de informatiewinkel te hoeven sluiten. Afhankelijk van een kosten/baten analyse kunnen we onderdelen van de bestaande data warehouse architectuur omzetten naar een virtuele aanpak, maar dat is zeker niet altijd nodig. Voor iedere nieuwe gegevensbron bekijken we of een fysieke of virtuele aanpak beter past. The best of both worlds! Afhankelijk van het doel dat we voor ogen hebben met bepaalde data, bepalen we in vier stappen de plek in de architectuur van het logisch data warehouse.
- Wat zijn de informatiewensen?
- Waar zijn de benodigde data opgeslagen en wat zijn de (on)mogelijkheden
- Wat zijn de eisen en wensen m.b.t. de informatievoorziening
- Spreken de informatie en onderliggende data elkaar niet tegen (hierover een andere keer meer…)
‘One size’ past niet altijd
Het mooie van het logisch data warehouse is dat de architectuur zowel een fysieke als virtuele aanpak ondersteunt. Het is geen one-size-fits-all architectuur waarin elke informatiebehoefte op dezelfde manier verwerkt en gepresenteerd moet worden. Ik heb vooral laten zien dat de stap om je klassieke data warehouse om te zetten naar een logisch data warehouse echt niet zo groot is. Een zorg die ik nogal eens tegenkom bij bedrijven die datavirtualisatie overwegen. Ik hoop dat ik die zorg weg heb kunnen nemen en je mag verwelkomen in de virtuele wereld van het logisch data warehouse!
Want welke alternatieven heb jij voor de alsmaar sneller groeiende behoefte aan data binnen je organisatie?