
Leer in 12 minuten
- Wat sterke use cases voor datavirtualisatie zijn
- Hoe je tot een goede Proof of Concept komt
- Hoe je je organisatie voorbereidt op datavirtualisatie
Je hebt van alles over datavirtualisatie gelezen en je bent eruit: dit is iets voor jouw bedrijf. Maar hoe kies je nu het juiste datavirtualisatieplatform? En waar moet je op letten om datavirtualisatie tot een succes te maken? Want het gaat daarbij niet alleen over techniek, maar ook over je businessdoelstellingen en de werkwijze van je organisatie. In deze blog nemen we je stap voor stap mee.
Datavirtualisatie: waarom ook alweer?
Laten we eerst nog even kort kijken waarom datavirtualisatie zo aantrekkelijk is. Doordat je een virtuele laag over je data-architectuur legt, kun je data uit al je (bron)systemen en databases snel en flexibel integreren. Je hoeft geen data te kopiëren of te migreren en het is ook niet nodig je zorgen te maken over verschillende informatiedefinities. In plaats daarvan kun je vertrouwen op één versie van de waarheid. En terwijl je als IT vanuit één platform je data efficiënt onder controle houdt, hebben gebruikers overal in je organisatie via virtuele tabellen eenvoudig toegang tot de benodigde gegevens om in hun specifieke informatiebehoefte te voorzien – op een manier die voor hen het beste werkt. Dat komt de productiviteit van IT en de business ten goede.
Ook het beveiligen van de datatoegang regel je centraal met datavirtualisatie. En je weet altijd waar gegevens vandaan komen. Die transparantie helpt je organisatie ook aan de eisen van interne en externe audits en aan regelgeving te voldoen.
Use cases voor datavirtualisatie
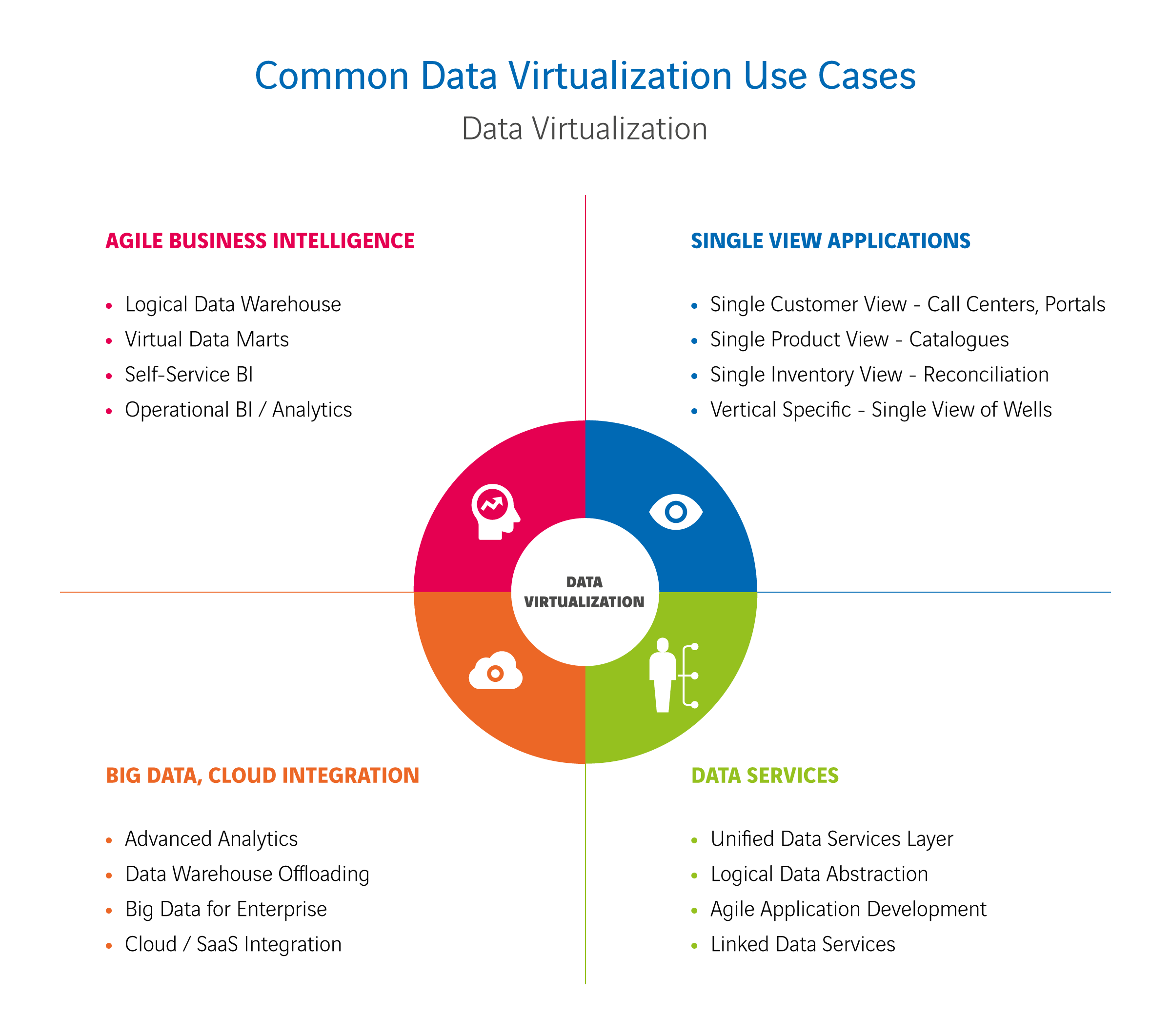
Met de voordelen die we net noemden, helpt datavirtualisatie je uitdagingen in verschillende situaties aan te gaan. We geven je wat voorbeelden van sterke use cases op diverse gebieden:
- Migratie
Denk aan een use case als systeemmigratie: de overstap van een klassiek CRM-systeem naar een cloudoplossing. Of aan een gefaseerde overgang van legacysystemen naar de cloud. Met datavirtualisatie kun je dat zónder operationele downtime of het stopzetten van rapportages. - Agile BI
Met datavirtualisatie kun je je data gebruiken voor governed (gereguleerde) en selfservice BI, maar ook voor data science en API- of systeemkoppelingen. Bovendien is het ideaal voor ‘agile’ BI, waarbij je in heel korte cycli van proberen, piloten en productie tot dashboards en rapportages komt. Wil je SaaS-cloudtoepassingen zoals Salesforce of Google Analytics als nieuwe bronnen aansluiten bij je bestaande BI-stroom? Dat kan! Met datavirtualisatie combineer je alle data met elkaar, zelfs in een hybride landschap. En over de beveiliging hoef je niet in te zitten, die is immers centraal geregeld. - Ontsluiten van (real-time) data
Presteert een bronsysteem niet goed bij het (near) real-time ontsluiten van grote hoeveelheden data en staan je SLA-afspraken onder druk? Met datavirtualisatie kun je historische data ‘offloaden’ naar een andere bron en combineren met real-time data uit het bronsysteem. Ook door systemen slimmer te bevragen of optimalisaties via caching voorkom je overbelasting van je bronsystemen. Zelfs near real-time analytics op big data is mogelijk, zonder eerst allerlei data te kopiëren met ETL-processen. En je combineert probleemloos een oud datawarehouse met een nieuwe databron tot een virtuele datamart.
Use cases uitwerken in Proof of Concept
Een datavirtualisatieplatform aanschaffen en implementeren doe je niet zomaar. Het is een grote investering en een beslissing die de kern van je data-architectuur raakt. Dat brengt ingrijpende veranderingen met zich mee. Een Proof of Concept helpt je zoals altijd de beste keuze voor een oplossing te maken. Daarbij is een grondige voorbereiding cruciaal. Allereerst moet je goed nadenken welke use cases je in je Proof of Concept wilt uitwerken. Waar liggen de mogelijkheden om met datavirtualisatie verbeteringen te realiseren? De volgende stap is de uses cases goed te beschrijven. Om welke (deel)processen binnen de organisatie gaat het? Waar beginnen en waar eindigen ze? En hoe leveren ze waarde aan de organisatie?
Verwachtingen en eisen in kaart brengen
Na het beschrijven van de use cases is het zaak om de verwachtingen en vereisten van je stakeholders te inventariseren. Dit zijn alle partijen die bij het keuzeproces zijn betrokken en straks te maken krijgen met het gekozen datavirtualisatieplatform. Denk hierbij zeker aan de business en IT, maar vergeet ook niet de wensen en eisen vanuit architectuur, governance of bijvoorbeeld inkoop in kaart te brengen. Zo’n inventarisatie kun je aan de hand van interviews of workshops doen, afhankelijk van de mogelijkheden. Heb je alle verwachtingen en vereisten op een rij? Dan vertaal je ze naar ‘Proof Points’. Dat zijn de aspecten en eigenschappen die je wilt aantonen in je Proof of Concept. Op deze Proof Points ga je de datavirtualisatie-oplossing dus beoordelen.
Proof Points koppelen aan use cases
Beperk jezelf niet bij het benoemen van Proof Points. Het is beter om in eerste instantie te veel of zelfs tegenstrijdige Proof Points te hebben, dan aspecten over het hoofd te zien. Dat komt later helemaal goed bij het kwalificeren van de punten. Dan haal je niet alleen dubbele Proof Points of Proof Points die met elkaar of met je data-architectuur conflicteren van je lijst af. Je beoordeelt ook de verschillende aspecten of eigenschappen op hun waarde – sommige zullen belangrijker zijn dan andere. Zo kom je tot de Proof Points die je daadwerkelijk hard wilt maken in je Proof of Concept.
De Proof Points die je overhoudt, koppel je aan de geïnventariseerde use cases. Zorg dat je alle punten ‘afdekt’ bij de invulling van je use cases, maar minimaliseer het aantal use cases. Het doel van je Proof of Concept is aantonen dat het datavirtualisatieplatform dat je wilt kiezen geschikt is. Je focus ligt dus op de Proof Points, niet op de use cases zelf.
Punten die voor alle use cases gelden
Naast de Proof Points voor je specifieke use cases, heb je ook te maken met zaken die voor iedere toepassing van datavirtualisatie belangrijk zijn, in iedere situatie. Dit soort aspecten zijn bijvoorbeeld security en performance, daar hebben we het al eerder over gehad. Maar er zijn méér algemene punten waarop je de Proof of Concept voor je datavirtualisatieplatform op moet toetsen. Dit zijn onder andere:
- Diversiteit van gegevensbronnen
Je datavirtualisatieplatform moet alle bronsystemen en technologieën waarin gegevens zijn opgeslagen kunnen ontsluiten. - Diversiteit van ontsluiting van data
Ondersteuning van alle API’s, talen en bestandsformaten waarin datagebruikers vragen stellen en waarin je data aan hen levert, is essentieel. - Datatransformatie
Het moet mogelijk zijn data uit je gegevensbronnen ingrijpend te transformeren voor ze naar je datagebruikers gaan. Transformaties zijn bijvoorbeeld filters, berekeningen, aggregaties en integraties. - Datamanagement
Je wilt het datavirtualisatieplatform samen met alle gedefinieerde specificaties kunnen beheren en monitoren. Dit betekent dat je mogelijkheden nodig hebt als data lineage analyses, impactanalyses, uitgebreid en gedetailleerd loggen en autorisatie- en authenticatieregels definiëren. - Documenteerbaarheid en doorzoekbaarheid
Je datavirtualisatieplatform moet kunnen samenwerken met je bestaande data catalog voor het documenteren of kunnen dienen als geïntegreerde data catalog van alle gedefinieerde objecten. Belangrijk is dat je concepten aan deze catalog kunt toevoegen en dat alle documentatie doorzoekbaar is. Zodat gebruikers zelf kunnen zoeken naar geschikte gegevens voor hun rapporten. - Databaseserver onafhankelijkheid
Samenwerking met diverse databases, on-premise en in de cloud, zoals Microsoft SQL Server, Oracle en PostgreSQL, maar ook Snowflake en Azure DB, moet mogelijk zijn. Ook in de toekomst mag je niet beperkt zijn bij de inzet van nieuwe databases. - Query optimalisatie
Ondersteuning van een geavanceerde query optimizer zorgt voor goede prestaties. Liefst ga je voor een cost-based query optimizer, die bij het uitvoeren van een query rekening houdt met de eigenschappen van gegevens en die technieken ondersteunt voor een efficiënte koppeling van meerdere bronnen. Ook transparantie is een randvoorwaarde, zodat een ontwikkelaar in detail kan zien hoe een vraag wordt verwerkt. - Caching
Je moet de queryresultaten die binnen je datavirtualisatieplatform worden opgebouwd, kunnen cachen. Dit betekent dat de software deze data fysiek opslaat voor hergebruik. Dit is soms nodig om gegevensbronnen niet te veel te belasten en de prestaties te verbeteren of om een consistent gegevensresultaat over een bepaalde periode te tonen. - Query pushdown
Om de verwerkingskracht van je database optimaal te gebruiken, wil je dat query’s die op het datavirtualisatieplatform binnenkomen zo veel mogelijk worden doorgestuurd naar de onderliggende database(s). Dit heet query push-down. - Lokale ondersteuning en lokale klanten
Het is belangrijk dat het datavirtualisatieplatform dat je kiest in Nederland wordt ondersteund, door de leverancier zelf of door een consultancyorganisatie. Kijk ook of er in Nederland andere klanten zijn die de oplossing gebruiken. En of de leverancier ons land als een volwassen markt beschouwt. - Volwassenheid
Onderzoek of het datavirtualisatieplatform zich bij andere klanten heeft bewezen. Het moet robuust zijn en je moet erop kunnen vertrouwen.
 Andere manier van werken nodig
Andere manier van werken nodig
Heb je op basis van je Proof of Concept het ideale datavirtualisatieplatform gekozen? Dan denk je misschien dat je er bent en dat het succes van je datavirtualisatieplannen is verzekerd. Maar dat succes wordt uiteindelijk ook door hele andere zaken bepaald. Want als je dingen blijft doen zoals je ze deed, krijg je wat je kreeg. Met andere woorden: de grote vraag is of je bij de inzet van datavirtualisatie in staat bent om je werkwijze daaraan aan te passen! We zetten de belangrijkste aandachtspunten voor je op een rij:
- Ga voor agile development en deployment
Datavirtualisatie vraagt een agile manier van werken, geen complexe OTAP-procedures of watervalmethode. Je speelt het spel van development en deployment in een cyclus van Proberen, Pilot, Productie. Voorwaarde voor een succesvolle ‘walk the agile talk’ is wel dat je alle verschillende activiteiten onder controle hebt en dat ze met elkaar in balans zijn. Alleen zo ga je echt sneller ontwikkelen en nieuwe functionaliteit in gebruik nemen. - Regisseer lokaal en geef decentraal vrijheid
Je bent het niet gewend, maar het is wel wat er gebeurt: met datavirtualisatie gaan je gebruikers zelf aan de slag met data. Wil bijvoorbeeld marketing, data science of het actuariaat van je bedrijf iets uitproberen? Dan hoeven ze niet naar de IT-afdeling om een nieuwe datamart te vragen, maar kunnen ze zelfstandig met data experimenteren in virtuele tabellen die ze zelf samenstellen. Zelfs data uit eigen bronnen toevoegen is daarbij mogelijk. Die vrijheid kun je ze met een gerust hart geven. Want met datavirtualisatie veranderen je gebruikers je data niet. Bovendien zijn de regie over je data en de security centraal geregeld en is de herkomst van gegevens altijd volledig transparant. Je hoeft je dus geen zorgen te maken over data-integriteit, verkeerde interpretaties of compliance. - Blijf meebewegen
De overgang naar de cloud, systeemmigratie, een data-architectuur die verouderd is. Er zijn doorlopend veranderingen en die houd je ook niet tegen. Stop dus met zoeken naar dat ene product dat alles oplost, die race win je nooit. Met datavirtualisatie ontkoppel je je bronnen van je datagebruik. Zo kun je stap voor stap migreren en mee blijven meebewegen in een passend tempo, waarbij je je organisatie ondersteunt in plaats van technologie pusht. - Denk in gelaagde oplossingen
Probeer niet om zo veel mogelijk datatransformaties in één keer samen te voegen. Het is beter om in gelaagde oplossingen met gestapelde virtuele tabellen te denken en zo de mogelijkheden voor hergebruik en aanpassing van data en datastructuren te maximaliseren. Voor traditionele ETL-denkers lijkt dat misschien een performance-nachtmerrie, maar daar hoef je echt niet bang voor te zijn. Want in de praktijk gaat je dataset niet door al die gestapelde views heen, maar worden die gestapelde views uiterst efficiënt herschreven en gesimplificeerd naar query’s op de bronnen.
De moraal van dit hele verhaal? Het is belangrijk om met een goede proof of concept het juiste datavirtualisatieplatform te kiezen, maar nog belangrijker is het besef dat je als organisatie moet veranderen om de voordelen van datavirtualisatie te benutten. Wil je dat? En kun je dat? Ook dat moet je eerst uitproberen voordat je kiest.
Hoe zet jouw organisatie datavirtualisatie optimaal in?