
Leer in 11 minuten
- Waarom ontkoppelen eigenlijk niet de juiste term is
- Waarom je koppelpunten en spelregels nodig hebt in je architectuur
- Welke use cases zich goed lenen voor slim koppelen
Als we het hebben over het ontwerpen van een nieuwe, moderne data-architectuur, komt de term ‘ontkoppelen’ nogal eens voorbij om een bepaald principe uit te leggen. Ook in literatuur over datavirtualisatie wordt dit principe regelmatig aangehaald:
“Datavirtualisatie ontkoppelt dataconsumenten van databronnen. Voor een dataconsument lijkt het alsof alle data zich in één grote, geïntegreerde database bevindt, terwijl deze data verspreid is over verschillende databronnen. Alle data kan met één en dezelfde taal benaderd worden, ongeacht welke taal de onderliggende databron ondersteunt.”
Bron: Data Virtualization for Business Intelligence Systems, Rick van der Lans
Ontkoppelen is een zeer belangrijk principe om flexibiliteit te waarborgen, maar eigenlijk is het jammer dat we er deze naam voor hebben gekozen. Een data-architectuur is immers toch juist bedoeld om te koppelen? Gebruikers met data. Applicaties met gebruikers. Operationele systemen met een centraal dataplatform. Alles draait om koppelen. Vandaar mijn stelling: niet ontkoppelen, maar slim koppelen! Doordat we de term ‘ontkoppelen’ gebruiken, is het voor veel mensen moeilijk te begrijpen wat we nu precies bedoelen. In dit artikel wil ik het daarom eens goed uitleggen.
Ontkoppelen met verbinding
Veel van de data warehouses die zo’n 20 tot 30 jaar geleden werden ontworpen hadden ook ontkoppelen als uitgangspunt. Door alle data volledig te kopiëren vanuit de bronsystemen ontstond letterlijk een ontkoppeling: rapportage tools hadden geen enkele directe verbinding meer met de bronsystemen. Dit gaf onbeperkte vrijheid voor het data warehouse om de gegevens te verwerken. Maar juist omdat de verbinding met de bronsystemen ontbrak, ontstonden allerlei problemen op het moment dat er zaken gewijzigd moesten worden. Een wijziging in een bronsysteem kon grote impact hebben, laat staan de gevolgen van een complete vervanging van een bronsysteem. Dit is precies de reden dat bedrijven naar oplossingen voor datavirtualisatie gingen kijken. Ook dan is er een ontkoppeling, tussen de bronsystemen en de ‘virtuele database’, maar de verbinding blijft wel in stand en wijzigingen kunnen veel eenvoudiger en sneller opgevangen worden.
Focus op spelregels
Maar terug naar mijn stelling. Als alles met alles verbonden is, gaat het dus om slim koppelen. Wat dat betekent? Dat je het aantal ‘koppelpunten’ in je architectuur minimaliseert. En dat de focus ligt op de spelregels waarmee de onderdelen van je architectuur verbonden zijn. Wat moet er gebeuren op welk koppelpunt? Waarmee doe je dat? En wanneer doe je dat? Die spelregels moeten er voor zorgen dat wijzigingen of uitbreidingen zo weinig mogelijk impact hebben in tijd en geld.
Dat klinkt misschien abstract, maar die spelregels zijn heel concreet. Ze geven antwoorden op vragen als:
- Waar wordt de verbinding met de bronsystemen vastgelegd?
- Waar wordt data opgeschoond of gefilterd voordat het verder verwerkt wordt?
- Waar worden gegevens gecombineerd en geïntegreerd?
- Waar wordt het informatiemodel (KPI’s, rekenregels, feiten en dimensies) vastgelegd?
- Waar worden berekeningen en rekenregels uitgevoerd?
- Waar worden data services gedefinieerd?
- Waar worden toegang en data-autorisatie geregeld?
Kaartenhuis
Het minimaliseren van de koppelpunten en het toepassen van goede spelregels, voorkomt dat er een kaartenhuis van koppelingen ontstaat, waarbij een kleine wijziging grote gevolgen kan hebben. Je zou kunnen zeggen dat er een grote mate van ontkoppeling is, op basis van slimme verbindingen.
Een goed voorbeeld is de spelregel bij wijzigingen in een bronsysteem, bijvoorbeeld een wijziging van een kolomnaam of het aanpassen van een datatype. Uiteraard wil je dit automatisch detecteren, maar vervolgens moet er één koppelpunt zijn waar deze wijzigingen volgens vaste spelregels snel worden opgevangen. Zonder dat de informatievoorziening verstoord wordt of rapportages of dashboards ‘omvallen’.
Een voorbeeld van een koppelpunt zijn zogenaamde interface views. Dit zijn views waarin de definitie van een dataweergave is vastgelegd: kolommen, datatypen en definities. Je zou dit de fysieke implementatie van een gegevenslevering-overeenkomst kunnen noemen. Met rapportageontwikkelaars of systeemeigenaren kan de spelregel worden afgesproken dat de interface views het koppelpunt zijn voor data-uitwisseling. Bij grote wijzigingen kan een nieuwe implementatie view gemaakt en getest worden (de view die data levert aan de interface view). Als deze gereed is, kan eenvoudig de switch worden gemaakt. Zo komt de stabiliteit van de dataleveringen nooit in gevaar.
Goede spelregels gaan uit van vier principes:
- Zo min mogelijk koppelpunten
- Geen zaken dubbel uitvoeren
- Zo eenvoudig mogelijk aanpassingen kunnen doorvoeren
- Zoveel mogelijk generiek en geautomatiseerd werken
Twee koppelpunten
Helaas ontbreekt het in de praktijk vaak aan duidelijke koppelpunten en eenduidige en heldere spelregels. In een eerder artikel heb ik al eens geschreven hoe je met datavirtualisatie slim koppelpunten kunt definiëren. In een vereenvoudigde weergave ziet dat er als volgt uit:
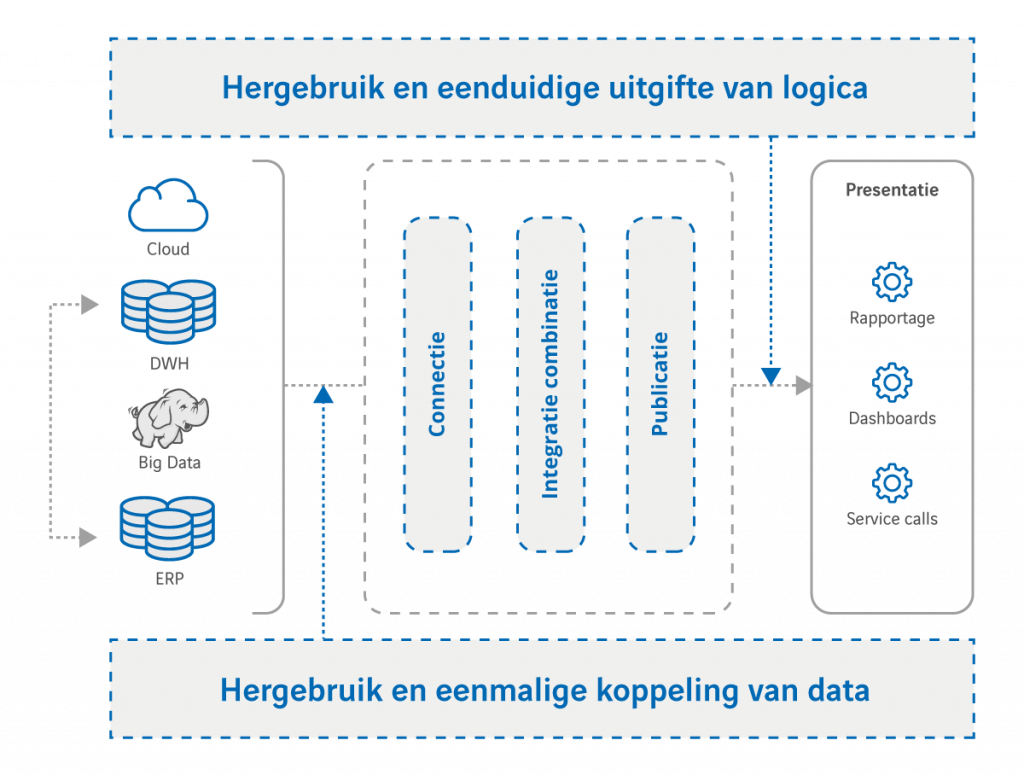
Hier is dus sprake van slechts twee koppelpunten:
- Het linkse koppelpunt zorgt voor de connecties naar de bronsystemen en lost de complexiteit van en tussen de bronsystemen op. Na dit koppelpunt moet data vrij bruikbaar en te combineren zijn.
- In het rechtse koppelpunt wordt alle logica van de data vastgelegd en hergebruikt. Datagebruik en logica zijn dus strikt gescheiden en worden nooit vermengd!
Op deze manier staan de ‘verpakkingsvorm’ van de data (webservice, tabel, dataset) en de gebruikte rapportage- en analyse-tools helemaal los van de toegepaste transformaties en rekenregels in het informatiemodel (koppelpunt 2) en van de broncomplexiteit en -variatie (koppelpunt 1). In de praktijk zeggen we dan dus: “datavirtualisatie ontkoppelt dataconsumenten van databronnen”.
Use cases
Waarom zou je beginnen met slim koppelen via datavirtualisatie? Omdat er steeds meer use cases komen die niet eenvoudig zijn op te lossen met je bestaande data-architectuur. Soms zijn dat zeer urgente situaties, bijvoorbeeld als een belangrijk operationeel systeem, waar veel rapportages van afhankelijk zijn, wordt gemigreerd of vervangen. Of als toezichthouders nieuwe eisen stellen aan de vorm en snelheid van informatievoorziening. Maar vaak spelen er ook allerlei andere wensen in een organisatie die nu niet opgepakt worden omdat de data-architectuur daar niet geschikt voor is. Bijvoorbeeld bij informatie-intensieve afdelingen als Finance en Marketing die behoefte hebben aan data en waar veel andere afdelingen ook hun voordeel mee kunnen doen.
Ik neem drie verschillende situaties als voorbeeld.
- Meebewegen met migraties
Bedrijven die een nieuwe SaaS-dienst in gebruik nemen (Salesforce, SAP Cloud, Microsoft Dynamics 365 etc.) willen de data uit die omgeving graag (gefaseerd) opnemen in hun rapportages, zodat de ‘informatiewinkel’ netjes open blijft. Terwijl ondertussen gemigreerd wordt van on-premise naar cloud. Een complexe uitdaging. Omdat datavirtualisatie ervoor zorgt dat de koppeling met de verschillende bronsystemen (die in beweging zijn) losstaat van de integratie, combinatie en interpretatie van data (‘ontkoppeling’ van data en gebruik) kun je als het ware meebewegen met de verschuiving die plaatsvindt in de onderliggende systemen. Zonder complexe aanpassingen. Een enorm voordeel, zeker omdat dit soort systeemmigraties vaak lang duren en in fasen worden uitgevoerd.
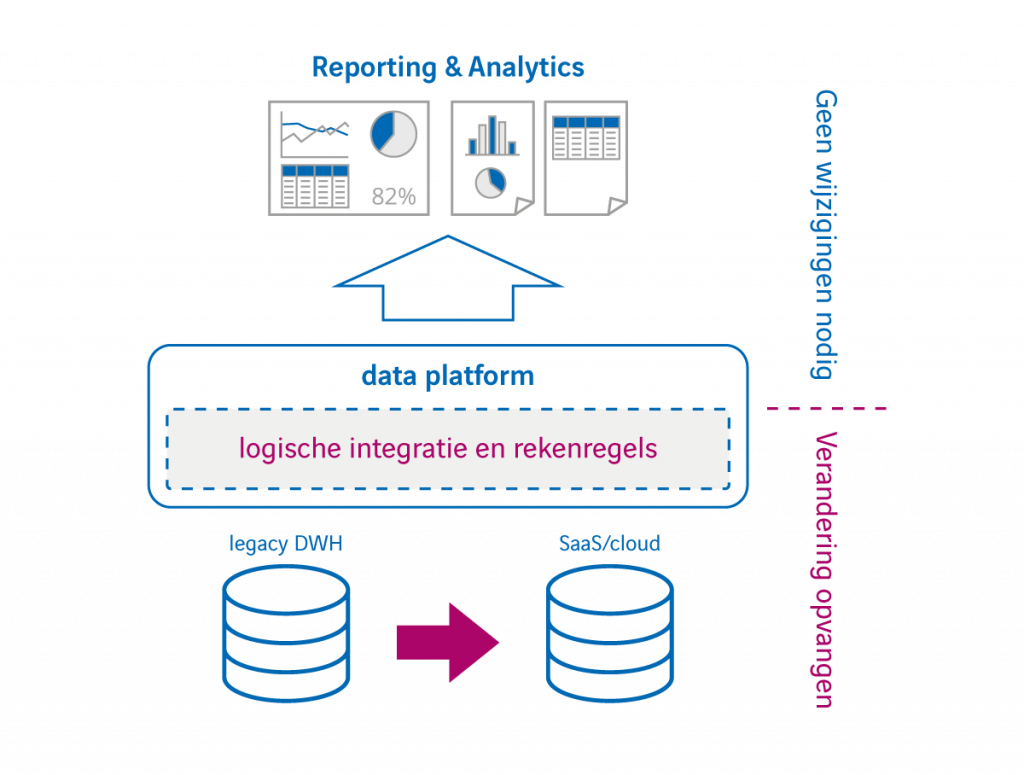
- Herverpakken van oude data warehouses
Veel organisaties hebben te maken met een verouderd data warehouse dat te complex geworden is (te veel koppelpunten en afhankelijkheden). Nieuwe bronsystemen toevoegen is duur en tijdrovend, terwijl data uit die systemen wel gebruikt moet kunnen worden voor rapportage en analyse. Door het bestaande data warehouse als bronsysteem te zien van het datavirtualisatieplatform, kan ook een ‘ontkoppeling’ bereikt worden van de bestaande DWH-complexiteit. Data uit het data warehouse kan vervolgens eenvoudig gecombineerd worden met gegevens uit andere systemen. Bij een toekomstige migratie van het data warehouse naar een moderne data-architectuur, kan – zoals in het vorige voorbeeld beschreven – de informatiewinkel gewoon open blijven.
- Een datawinkel
Steeds meer bedrijven zien datagebruik als een business activiteit en niet iets van (alleen) de IT-afdeling. Daarbij wordt vaak gesproken van het ‘ontkoppelen’ van datalevering en datagebruik, of van de ‘datastraten’ en de ‘datawinkel’. Het concept van een datawinkel is natuurlijk aansprekend. Een winkel met data- en informatieproducten die naar eigen inzicht kunnen worden gebruikt. Waarbij de inhoud en de toegepaste logica van de producten in de winkel centraal staan. De verpakking van de producten (webservice, tabel, dataset, rapport, dashboard) en de gebruikte tooling voor analyse en rapportage staan daar helemaal los van. De datawinkel zorgt voor de gewenste ontkoppeling. Een concept dat met behulp van datavirtualisatie, slimme koppelpunten en duidelijk spelregels uitermate goed ingevuld kan worden.
Snel en adequaat reageren
Of we het nu over ontkoppelen hebben of over slim koppelen, het doel is altijd het minimaliseren van de impact bij wijzigingen en uitbreidingen. De afgelopen jaren hebben we geleerd dat er slimme manieren van ontkoppelen zijn (datavirtualisatie) en manieren van ontkoppelen die uiteindelijk toch voor problemen zorgen (duplicatie en transformatie van data naar een data warehouse met vaak meerdere architectuurlagen). De belangrijkste les is dat, als je gebruikers ‘koppelt’ aan databronnen, je daarbij zo min mogelijk koppelpunten gebruikt voor maximale flexibiliteit en heldere en duidelijke spelregels hebt voor die koppelpunten. Nu bedrijven steeds intensiever gebruik maken van alle beschikbare data, wordt die aanpak des te belangrijker. Systemen veranderen, informatiebehoefte verandert, gebruikers veranderen. Alleen wie snel en adequaat kan reageren op die veranderingen is echt datagedreven.
Hoeveel koppelpunten heeft jouw data-architectuur op dit moment?