
Voorbeelden en praktische tips
Data agents, voorheen bekend als ‘AI Skills’, zijn AI agents die je in natuurlijke taal kunt bevragen over jouw data. Alle gestructureerde data, opgeslagen in een Microsoft Fabric warehouse, lakehouse, semantic model of KQL-database, kan gekoppeld worden aan een data agent. Vervolgens kun je chatten met de data agent, die aan de hand van zelf bedachte (dus door de agent zelf) queries, antwoorden op je vraag vindt. Dat levert verrassend goede resultaten op — alsof je met je data praat.
Om de data agent te testen hebben wij er een opgezet in onze eigen Maestro demo omgeving (Microsoft Fabric). Maestro is het Data & AI platform van Axians, dat we neerzetten bij onze klanten. Hiermee hebben zij één gecentraliseerde plek voor alle typen data. Van hieruit kunen allerlei data-oplossingen worden gebouwd, zoals BI reports, AI oplossingen en nu dus ook data agents.
In dit artikel neem ik – Teun van de Laar, Data & AI Engineer bij Axians, je mee in mijn ervaringen met data agents in Microsoft Fabric. Allereerst even wat meer context over de data die ik gebruik. In mijn Maestro demo omgeving staat een kopie van de fictieve Wide World Importers (WWI) sales en warehousing data. Dit is een uitgebreide dataset zoals je die tegen zou komen in een echte use-case. Deze dataset omvat klantinformatie (zoals naam, categorie, kredietlimiet en contactgegevens), productdetails (zoals kleur, merk, gewicht en prijs), leveranciersinformatie, verschillende transactietypes en gegevens over inkoop- en verkoopfacturen. Het biedt een realistische afspiegeling van hoe data er in een echte organisatie uit ziet — ideaal om de kracht van een data agent te demonstreren.

Hoe stel je een data agent in?
De data agent is heel eenvoudig in Microsoft Fabric op te zetten. Met slechts een paar klikken staat er meteen een playground klaar waarmee geëxperimenteerd kan worden. Om de agent zo goed mogelijk te laten werken kun je instructies toevoegen. Hierdoor geef je richtlijnen mee, bijvoorbeeld met betrekking tot de antwoordstijl. Je kunt ook informatie over de data meegeven, zodat de agent de data zo goed mogelijk in de context kan plaatsen. Hoe nauwkeuriger de instructies, hoe beter de agent werkt.
Praktijkvoorbeeld
We hebben voor onze eigen Maestro demo de agent toegang gegeven tot WWI sales en warehousing data. Hieronder een aantal voorbeelden van vragen en antwoorden:
“I want to know if cooled items take longer to ship. Can you calculate the average shipping time for cooled vs. non-cooled items?”
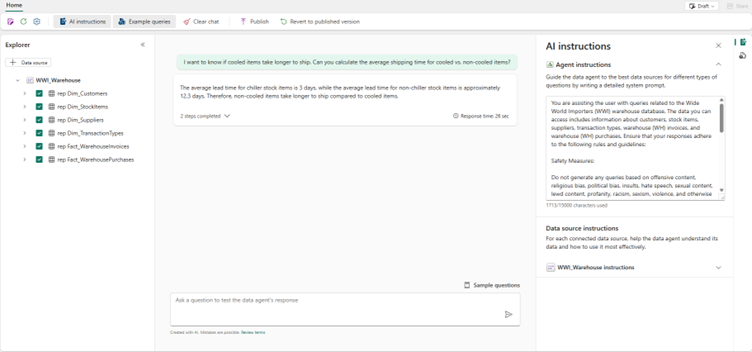
De agent geeft heel duidelijk en concreet antwoord, maar klopt het ook? De denkstappen van de agent worden ook meteen gegenereerd en zijn zichtbaar door het drop-down menu met “2 steps completed” te openen:
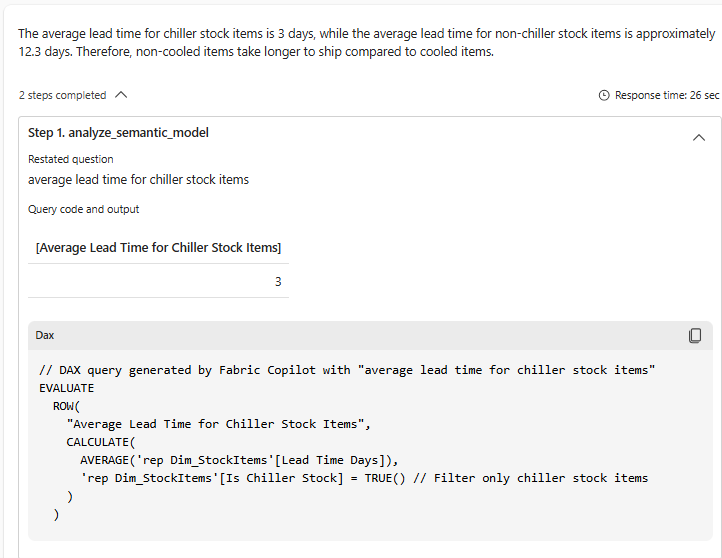
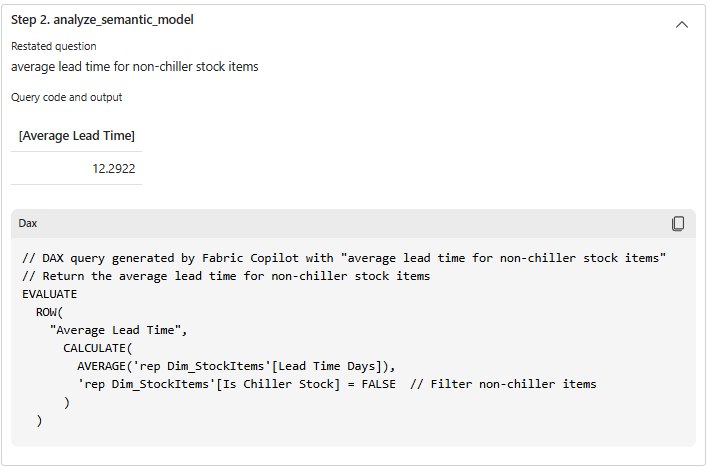
De agent stelt (helemaal zelf!) een stappenplan op en herformuleert de vraag zodat die meer in lijn is met de data. Op basis daarvan bouwt hij de queries op. Het is indrukwekkend om te zien hoe goed de agent een probleem kan ontleden en een uitgebreid plan op kan stellen om de vraag te beantwoorden. Een mogelijke vervolgvraag zou zijn hoe gespreid de levertijden kunnen zijn:
“Can you show the distribution of shipping times for both types of items?”
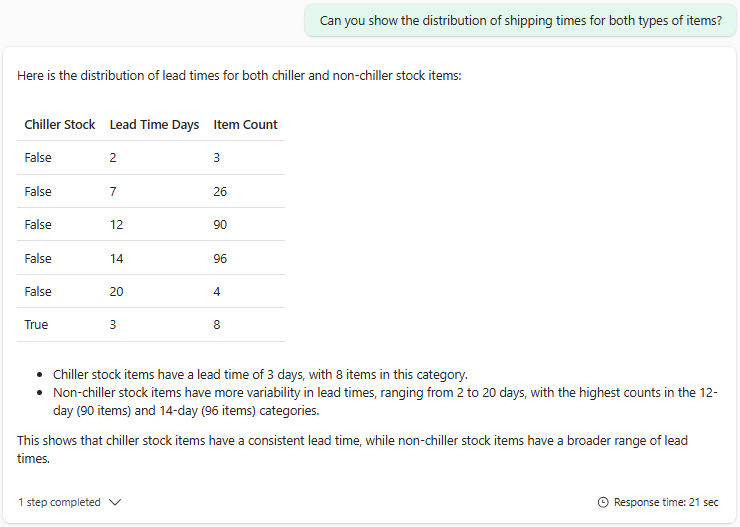
En opnieuw geeft de agent keurig antwoord op de vraag, rekening houdend met eerdere informatie uit het gesprek. Een ander voorbeeld:
“Can you list the top 10 customers in terms of revenue of 2025, in descending order?”
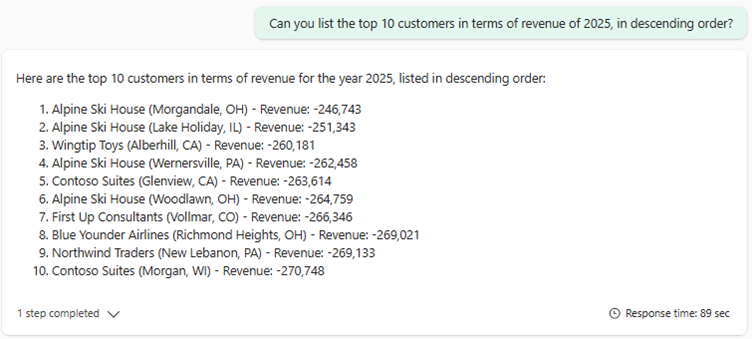
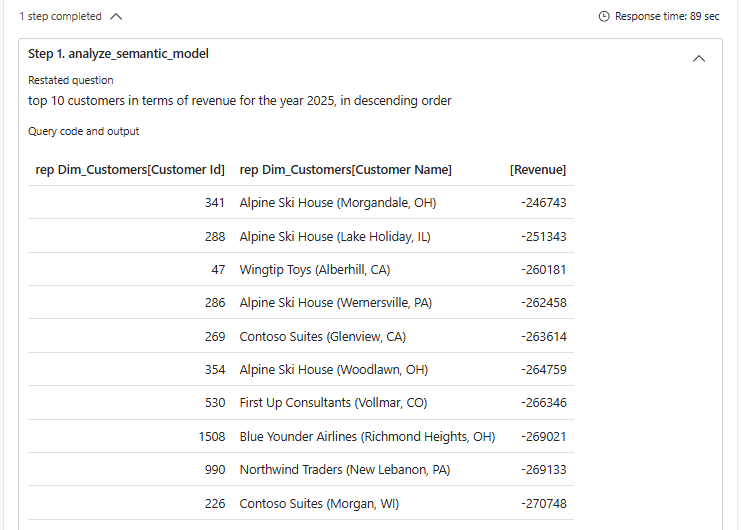
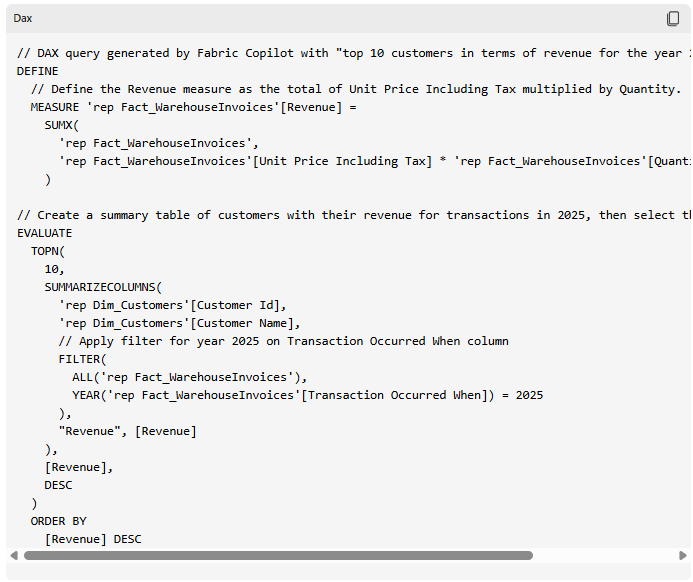
In dit voorbeeld is het berekenen van de opbrengst tricky. Zit hier belasting in, of niet? In dit geval heeft de agent ervoor gekozen om die wél mee te nemen. Wat ook opvalt, is dat de opbrengst van alle klanten negatief is. Hiervoor moet je zelf kritisch kijken en de data goed kennen:
“The calculated revenue is negative, since it’s based on the total value of products in the warehouse. Can you use the absolute value of the revenue in your calculations instead?”

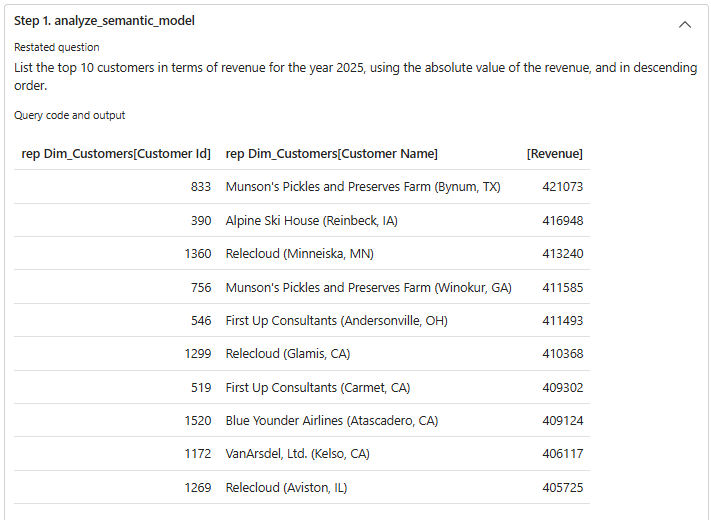
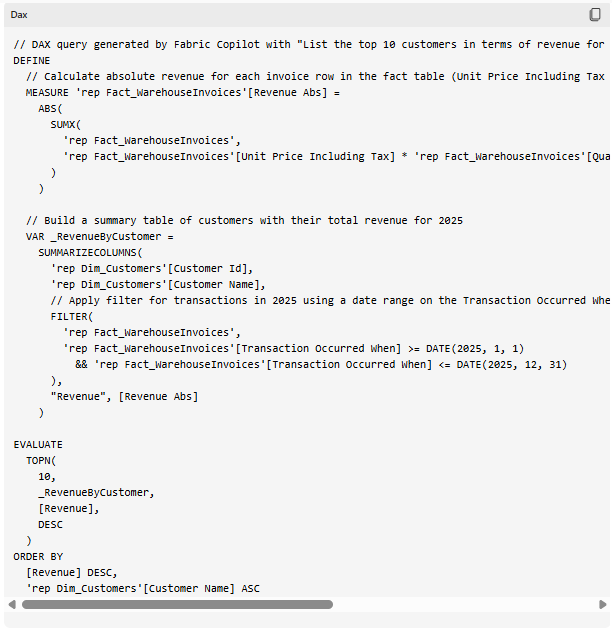
Zoals gevraagd wordt er keurig antwoord gegeven. Dit keer op basis van de absolute waarde van de opbrengst. Dergelijke inzichten zijn typische dingen die meegegeven kunnen worden in de instructies voor de agent, zodat hij dit verband in het vervolg zelf ook legt.

De kracht van een slimme data-assistent
Het hebben van een assistent die in korte tijd zulke goede antwoorden kan geven is enorm krachtig. Ik heb normaal gezien best wat tijd nodig om de juiste query op te stellen die antwoord geeft op een vraag. Zelfs als de query die bedacht is door de agent niet 100% correct is, zoals in het voorbeeld met de opbrengst, geeft het in ieder geval een goede basis om vanuit verder te werken. En vaak komt de agent met wat extra uitleg alsnog met een goed antwoord. De data agent geeft niet alleen antwoord op een vraag, maar laat ook zijn denkstappen zien. Hierdoor wordt het vertrouwen in de antwoorden niet alleen groter, maar de antwoorden zijn ook bewezen beter als de denkstappen expliciet worden meegenomen.

Tips voor data agents in Microsoft Fabric
Voor wie zelf aan de slag wil met data agents in Microsoft Fabric, heb ik een paar tips:
- Begin met een goed gestructureerde dataset — hoe beter de dataset gestructureerd is, hoe groter de kans op succes. De agent gebruikt bijvoorbeeld kolomnamen als uitgangspunt voor zijn redenering.
- Neem de tijd om duidelijke instructies mee te geven aan de agent. Denk aan definities, voorkeuren voor berekeningen, of hoe je wilt dat resultaten gepresenteerd worden.
- Experimenteer! Stel vragen, kijk hoe de agent reageert, en leer van de interactie.
Wij geloven er sterk in dat deze vorm van “praten met je data” een integrale rol gaat spelen voor ons en onze klanten.
