
Hoewel veel mensen intensief gebruik maken van rapportages, dashboards en BI- en analytics-tools, hebben ze vaak geen idee van het onderliggende informatiemodel en de beschikbaarheid, actualiteit en herkomst van de data die ze gebruiken. Terwijl deze kennis essentieel is om informatie optimaal te gebruiken en goed te interpreteren. Gebruikers stellen wel allerlei vragen, maar die zijn vaak niet zo eenvoudig te beantwoorden. Welke datasets en attributen zijn er beschikbaar voor mij? Waar komt die data vandaan en wat zijn de exacte definities ervan? Kan ik in het informatiemodel ook naar specifieke inhoud zoeken? Het is alsof je in een enorme bibliotheek een geschikt boek zoekt zonder dat er een index is. Dat is vrij kansloos. Net als bij een bibliotheek, zoeken we daarom naar manieren om mensen ‘wegwijs’ te maken in alle beschikbare data.
Uit een onderzoek van IDC, dat door de jaren heen regelmatig is geciteerd, bleek dat werknemers binnen een organisatie 30 procent van hun dagelijkse werktijd kwijt zijn met het zoeken naar correcte en bruikbare informatie voor hun dagelijkse werkzaamheden. Volgens het onderzoek kwam dit door het gebrek aan centraal geïndexeerde informatie en wisten medewerkers vaak niet hoe ze toegang konden krijgen tot die informatie. Nu, jaren later zijn de resultaten van dit onderzoek nog steeds actueel. Ondanks de forse investeringen die bedrijven hebben gedaan in technologie om data te verzamelen, te integreren en beschikbaar te stellen aan gebruikers. Die gebruiker ziet zich geconfronteerd met een scala aan databronnen – data warehouses, data marts, data lakes, on-premise systemen (ERP, financieel, logistiek), cloud systemen, social media en andere big databronnen – en kan ‘door de data de informatie niet meer zien’. En dat kost organisaties veel geld…
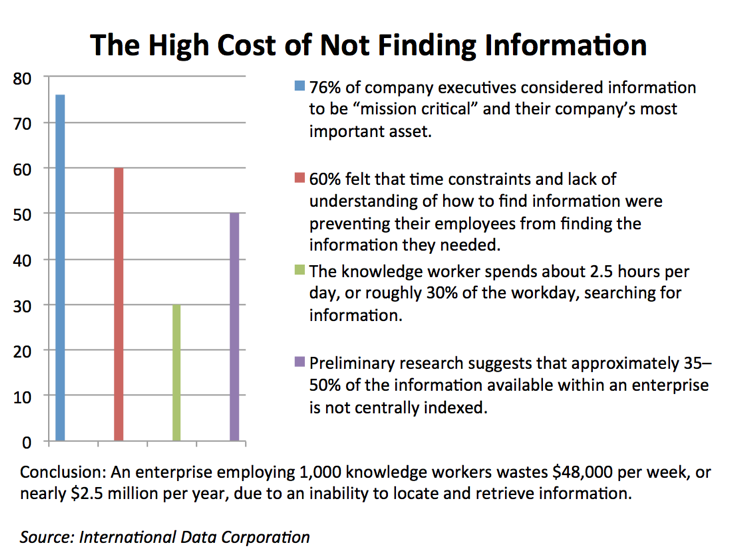
Niet te vinden
Veel data-initiatieven worden volgens een onderzoek van Gartner ’technologieprojecten’ die slechts beperkte waarde bieden. Er is vaak geen strategie om data goed te documenteren en van context te voorzien. Grote hoeveelheden verzamelde en opgeslagen data worden onvindbaar, onbetrouwbaar en bijna onbruikbaar. En organisaties verliezen uit het oog waar informatie zich bevindt. Daardoor is het steeds moeilijker geworden voor gebruikers om te controleren waar data vandaan komt en of informatie klopt. Soms is data zelfs helemaal niet te vinden. Volgens Forrester gaat 64 procent van de tijd bij dataprojecten verloren aan het identificeren welke data echt nodig is om een project uit te voeren. Gebruikers zijn nog steeds meer tijd kwijt aan het zoeken naar en interpreteren van informatie, dan dat ze besteden aan het gebruik ervan om waardevolle inzichten te krijgen.
Voor gebruikers is het essentieel dat ze informatie goed kunnen interpreteren. Want als ze snappen waar ze naar kijken, kunnen ze ook controleren of de data klopt en aanpassingen voorstellen als dat nodig is. Maar de noodzaak om te begrijpen waar data vandaan komt en waar het opgeslagen staat komt ook van buiten. Wet- en regelgeving wordt steeds strenger, maar bedrijven hebben moeite om te bepalen wie toegang heeft tot welke informatie. Daardoor wachten gebruikers vaak (te) lang op toestemming om data te mogen gebruiken. Of ze hebben juist, door een gebrek aan restricties, toegang tot informatie die zij helemaal niet mogen inzien. Vooral dat laatste scenario is natuurlijk totaal onwenselijk.
Vindbaarheid, begrijpelijk en veilig
Logisch dat bedrijven willen dat data eenvoudig vindbaar wordt voor gebruikers en begrijpelijk is voor de mensen die met de gegevens werken. Op een manier waarbij gebruikers in staat zijn zelf snel te zoeken naar gegevens die ze nodig hebben (of kunnen gebruiken) en ze die gegevens ook kunnen beoordelen op geschiktheid, relevantie, betrouwbaarheid, kwaliteit en actualiteit. En waarbij ze die gegevens vervolgens eenvoudig kunnen openen in een BI- of analyse-tool.
Vanuit de techniek denken we dan al snel aan het doorzoekbaar maken van metadata, maar er is heel wat meer nodig dan dat. Metadata kunnen doorzoeken is handig, maar metadata is helaas niet altijd goed beschreven of soms helemaal niet aanwezig (zoals in sommige big data bronnen). Als je kijkt naar tabel- en kolomnamen of schema’s van databases of applicaties zijn die vaak erg cryptisch beschreven. En databases waar het schema al 5 á 10 jaar van bestaat, hadden toentertijd nog vaak te maken met allerlei restricties voor naamgeving. Dit maakt veel metadata niet erg leesbaar voor gebruikers. Je wil mensen daarom graag de mogelijkheid geven om ook de data zelf te doorzoeken. Niet alleen op basis van ‘tags’, zoals in Google, maar ook met ‘data steward-achtige’ vragen over herkomst, onderhoud en betekenis van data. En dat ze die databronnen en de onderliggende metadata vervolgens zelf kunnen uitbreiden met documentatie, beschrijvingen en tags. Met als doel om de standaard metagegevens (zoals kolomnamen en gegevenstypen) zoveel mogelijk context te geven. Daarnaast zouden gebruikers in staat moeten zijn om nieuwe databronnen te registreren, die collega’s vervolgens kunnen vinden, begrijpen en gebruiken.
Vanuit de organisatie is het wel belangrijk dat gebruikers in een veilige omgeving werken en dat het gegevensgebruik voldoet aan de meest recente wet- en regelgeving. Data(gebruik) moet traceerbaar zijn en het moet duidelijk zijn welke gebruiker toegang heeft tot welke data. Zodat datalekken voorkomen worden en er te allen tijde verantwoording afgelegd kan worden over het gebruik van data.
Een catalogus voor de databibliotheek
In een eerder artikel legde ik uit hoe het datavirtualisatieplatform van Denodo op een logische manier data ontsluit en integreert, zonder dat replicatie van data nodig is. Met behulp van datavirtualisatie kun je snel en eenvoudig een virtuele ‘datahub’ creëren die toegang geeft tot alle data binnen en buiten je organisatie. Om data beschikbaar te stellen, hoef je die data immers niet meer (meerdere malen) te repliceren tussen allerlei ‘datalagen’. Toevoegen van databronnen en doorvoeren van wijzigingen gaat dan ook heel snel en eenvoudig. Bovendien kun je in Denodo makkelijk inzichtelijk maken hoe datasets tot stand zijn gekomen, wie toegang heeft tot welke data en welke informatie precies wordt uitgevraagd. Dat maakt een datavirtualisatieplatform ook de ideale ‘catalogus’ voor alle beschikbare data waar we naar op zoek zijn.
Het is dan ook niet voor niets dat Denodo met de recente versie 7.0 lancering de Dynamic Data Catalog introduceerde. Een self service webapplicatie waarmee gebruikers eenvoudig zoeken en navigeren door alle beschikbare data binnen het platform, zonder dat ze directe toegang nodig hebben tot de ontwikkeltools of onderliggende databronnen. Gebruikers kunnen deze ‘catalogus’ data zoeken en allerlei kenmerken van die data bekijken. Ook zien ze direct welke veranderingen er aan onderliggende informatiemodellen in Denodo gedaan zijn. Ze kunnen data voorzien van documentatie, tags of categoriseren en eenvoudig toegankelijk maken via query’s. En ze hebben direct toegang tot de databronnen zelf via datavirtualisatie en beschikken dus altijd over actuele en relevante data.
Verbinding tussen rapportages en datamodellen
In de Dynamic Data Catalog kunnen gebruikers zelf nieuwe datasets toevoegen aan de datavirtualisatielaag, die vervolgens direct gepubliceerd worden in de Data Catalog en bruikbaar zijn door de hele organisatie. Zo blijft het niet een op zichzelf staand onderzoekstool, maar vormt het door de diepgaande integratie in het datavirtualisatieplatform juist de verbinding die gebruikers helpt om het grijze gebied tussen BI-tools en de onderliggende datamodellen beter te begrijpen. Het mooie van de Dynamic Data Catalog is bovendien dat na een zoektocht door de data de resultaten van een query meteen gebruikt kunnen worden in een BI-tool om ze verder te analyseren. Bijvoorbeeld door de VQL van een query te exporteren. Ook kunnen voorbeeldrapportages gedeeld worden met specifieke personen. Uiteraard kunnen medewerkers alleen informatie en (meta)data in de Data Catalog benaderen waar zij vanuit hun rollen en rechten toegang toe hebben.
De Dynamic Data Catalog
Bij het ontwerp van de Denodo Dynamic Data Catalog is het uitgangspunt geweest dat alle data die in een organisatie beschikbaar is aan vier voorwaarden moet voldoen: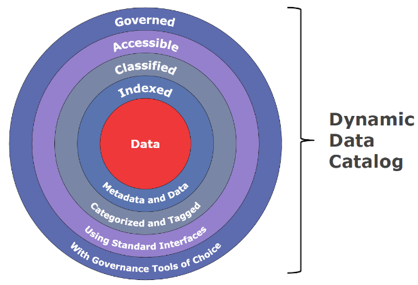
- Data is geïndexeerd via metadata en de data zelf
- Data is geclassificeerd met behulp van tags en/of categorisering
- Data is toegankelijk via queries om inzicht in die data te verkrijgen
- Data voldoet aan het data governance beleid van de organisatie
De belangrijkste functies van de Data Catalog zijn:
1. Catalogus van views en webservices
- Bladeren en zoeken naar een bestaande views en services
- Bekijken van beschrijvingen, relaties en herkomst van data
2. Zoeken en preview van data
- Zoeken op trefwoorden
- Snel data kunnen bekijken door preview query’s
3. Gebruiken van data
- Bestaande views aanpassen voor specifieke behoeften
- Een “mijn query’s” folder voor persoonlijk gebruik en delen van preview query’s
- Exporteren naar lokale bestanden
- Voorstellen van nieuwe standaard views
Om een idee te krijgen van het gebruik van de catalog, heb ik een paar voorbeelden op een rij gezet:
De algemene zoekbalk over de gehele Denodo Dynamic Data Catalog heen.
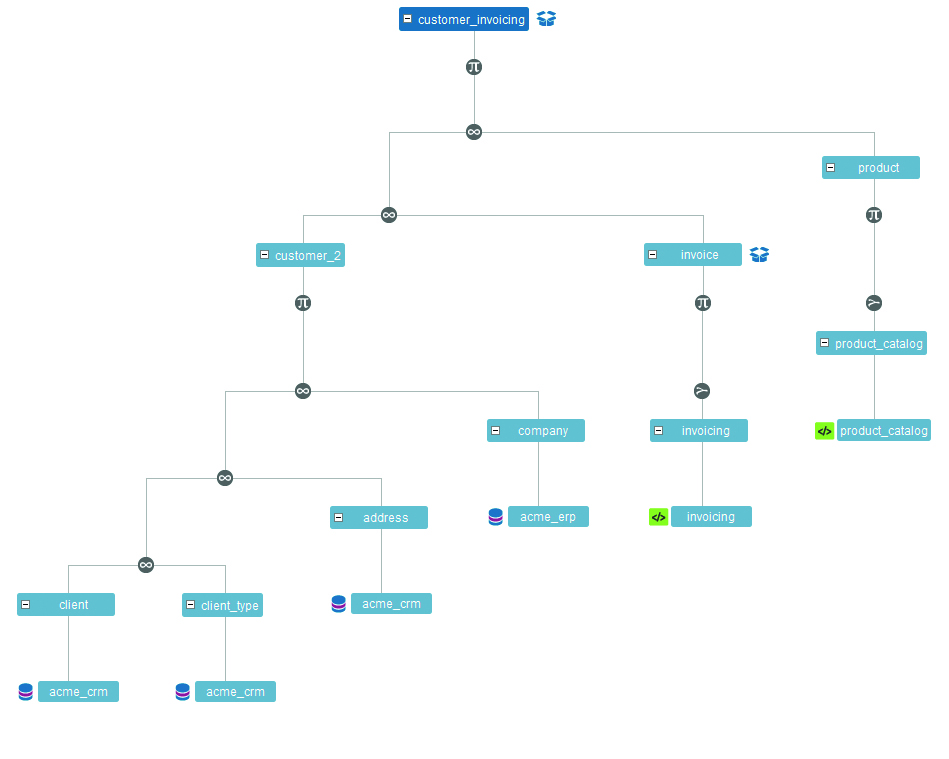
De Data Lineage van een volledige view bekijken. Hoe is deze view opgebouwd?
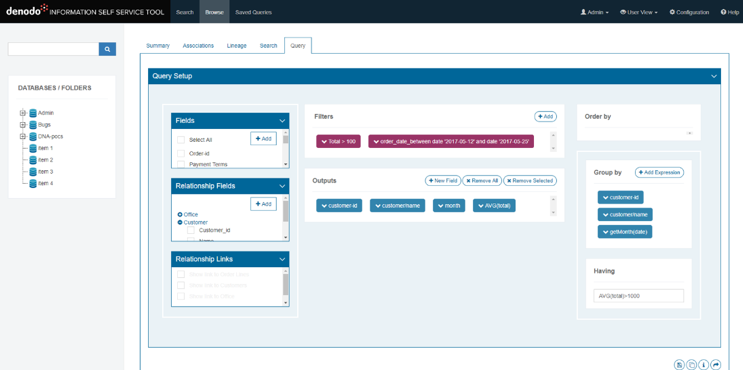
Het samenstellen van een ‘voorbeeld query’ met behulp van views en tabellen die te vinden zijn in de Denodo Dynamic Data Catalog.
De Denodo Dynamic Data Catalog geeft bedrijven zo een veilig en geavanceerd hulpmiddel in handen om op een hele makkelijke en toegankelijke manier antwoord te geven op allerlei vragen waar data-gebruikers mee worstelen. Zodat die snel te weten komen welke data er voor ze beschikbaar is, waar de ze die data vinden en wat ze ermee kunnen. En door de integratie in het datavirtualisatieplatform kunnen ze data direct bekijken, onderzoeken en in gebruik nemen!
De toekomst
In de dagelijkse praktijk ben ik veel bezig met datavirtualisatie en ik ben erg enthousiast over dit nieuwe product van Denodo. Omdat er altijd iets te wensen over blijft, ben ik ook uitermate benieuwd wat de toekomst nog gaat brengen op dit gebied. Daarom heb ik mijn oor eens te luister gelegd bij Rick van der Lans, die regelmatig spreekt met de hoofdarchitecten van allerlei producten – waaronder Denodo – over de nabije toekomstplannen. En hoewel hij niet alles los mag laten, wist hij mij het volgende te vertellen:
“Naarmate het ontwikkelen van rapporten en analyses steeds meer door business users en niet door IT-specialisten uitgevoerd wordt, wordt toegang tot beschrijvende informatie steeds belangrijker. Daarmee zal het belang van een data catalog of iets vergelijkbaars toenemen. Nu is het opvoeren en bijhouden van dat soort informatie een arbeidsintensief proces. In de toekomst zullen aan data catalogs ontologieën en thesauri toegevoegd moeten worden om de zoekfunctie te verbeteren. Bovendien verwacht ik veel van het inzetten van kunstmatige intelligentie om de beschrijvende informatie af te leiden van de gegevens zelf.”
Er staan ons dus nog mooie dingen te wachten!
Hoe ga jij zorgen dat gebruikers hun weg kunnen blijven vinden in de alsmaar toenemende hoeveelheid data?