
Datavirtualisatie staat hoog op de agenda van veel organisaties. Traditionele data warehouses kunnen de explosieve groei van datavolumes en gebruikersvragen niet meer bijbenen en steeds meer bedrijven zijn op zoek naar een alternatieve architectuur. Een Logisch Data Warehouse (LDW), waarbij data zo min mogelijk gedupliceerd wordt, is dan de voor de hand liggende keuze. Door data virtueel en niet fysiek te ontsluiten, kan sneller ingespeeld worden op veranderingen en kan nieuwe informatie veel sneller ontsloten worden. Daarmee is er pas echt sprake van agile BI.
Twee terechte vragen
Een professioneel datavirtualisatieplatform vormt het fundament onder een logisch data warehouse. Softwareproducten als Denodo Platform bieden de mogelijkheid om gegevensbronnen te integreren in een uniform informatiemodel zonder data te dupliceren, onafhankelijk van locatie of vorm. Met de mogelijkheden die zo’n platform biedt op het gebied van connectiviteit, autorisatie en performance-optimalisatie kunnen bedrijven enorm snel migreren naar een logische data warehouse architectuur. In de praktijk zie ik dat datavirtualisatie de verwachtingen vaak overtreft, maar dat veel organisaties worstelen met de investeringen in nieuwe software voor data-integratie. Ze stellen me eigenlijk steeds dezelfde twee vragen:
1. Uit welke alternatieven kan ik kiezen en wat zijn de verschillen?
2. Hoe kan ik de investeringen verantwoorden naar mijn organisatie?
Twee hele terechte en relevante vragen. Zo essentieel zelfs dat je ze in een zo vroeg mogelijk stadium moet beantwoorden.
Alternatieven
Wat betreft de alternatieven: die zijn er natuurlijk. En met grote verschillen in aanschafkosten. Maar ook hier geldt ‘goedkoop is duurkoop’! De beschikbare datavirtualisatie-oplossingen verschillen namelijk enorm in functionaliteit. Op hoofdlijnen doen ze misschien hetzelfde (het virtualiseren van datastromen), maar the devil is in the detail. De winst die je behaalt met een datavirtualisatieplatform is sterk afhankelijk van de (standaard)functionaliteit die de software je biedt. Overweeg dus zeker alternatieven, maar onderzoek vooraf voor elk alternatief goed de kosten en besparingen. Alleen dan kun je een goed afgewogen keuze maken op basis van een realistische business case.
Daarmee komen we meteen op de tweede vraag. Hoe onderbouw ik überhaupt de investering in software voor datavirtualisatie? In dit artikel leg ik uit hoe je in vier stappen een business case opstelt. Daarmee kun je niet alleen verschillende alternatieven vergelijken, die business case zal je snel duidelijk maken dat er met datavirtualisatie heel veel geld te verdienen is voor je organisatie!
Een business case in vier stappen
De business case moet aantonen dat de investering in datavirtualisatie gerechtvaardigd is. Ofwel: dat de opbrengsten hoger zijn dan de kosten. Daarvoor moeten we de benodigde kosten afzetten in de tijd tegen de verwachte opbrengsten. Voor elk alternatief dat je overweegt beantwoord je daarvoor de volgende vier vragen:
1. Welke kosten gaan we maken bij het implementeren van het nieuwe platform?
2. Welke kosten maken we in het huidige proces?
3. Welke besparingen levert het nieuwe platform ten opzichte van het huidige proces?
4. Welke kansen biedt het nieuwe platform en welke waarde hebben die?
1 – Implementatiekosten
We beginnen met de makkelijkste vraag: wat kost het om een datavirtualisatieplatform te implementeren en in de lucht te houden? Niet alleen initieel, maar ook de jaarlijks terugkerende kosten. Die kosten kunnen we in drie categorieën onderverdelen: licenties, infrastructuur en personeel.
Licentiekosten. Hoogte en vorm van licentiekosten zijn per product verschillend en vaak afhankelijk van het aantal servers (OTAP, productieclusters etc.) en CPU cores. Bereken vooraf goed welke licenties je nodig hebt voor jouw situatie. Een proof of concept op basis van realistische use cases kan daarbij helpen.
Kosten infrastructuur. Houd rekening met alle servers die je voor het datavirtualisatieplatform moet aanschaffen, aanvullend aan je bestaande infrastructuur. Denk ook aan databaseservers die het platform eventueel nodig heeft voor caching van data.
Personeelskosten. De kosten voor het inrichten van het platform, zijn sterk afhankelijk van de complexiteit van het platform, de beschikbare interne kennis en de benodigde externe expertise. Voor veel platformen zijn best practices beschikbaar die je een goede indicatie van de benodigde inspanning kunnen geven.
Met name in deze laatste categorie zitten grote verschillen tussen verschillende softwareproducten voor datavirtualisatie. Uitgebreide en volwassen platforms met veel standaardfunctionaliteit – zoals Denodo – zijn misschien duurder in aanschaf, maar dat verdien je dubbel en dwars terug in de eenvoud van installatie en configuratie. Ervaring met ETL en SQL is voldoende om aan de slag te kunnen met zo’n platform.
2 – Kosten van het huidige proces
In de tweede stap breng je de kosten in kaart van de processen waarmee je nu data ontsluit en die je wil vervangen met datavirtualisatie. Een voor de hand liggend voorbeeld is een traditioneel BI-proces: de keten van bronsysteem tot rapportage. Maar je kunt bijvoorbeeld ook kijken naar je dataloket: het leveren van informatie aan externe partijen. Wat kost het om je processen te beheren en wijzigingen door te voeren?
Het is belangrijk om inzicht te krijgen in de total cost of ownership (TCO) van het hele proces, van analyse, ontwikkeling, test en acceptatie tot deployment en beheer. Dit is een essentiële stap waarbij je als het ware een nulmeting doet. Je krijgt ineens inzicht in de kosten die je op dit moment maakt om informatie te ontsluiten en mijn ervaring is dat die analyse vaak behoorlijk confronterend is. Maar het is een noodzakelijke stap om te bepalen welke besparingen er te behalen zijn.
3 – De besparingen met datavirtualisatie
Nu wordt het interessant: wat gaat het datavirtualisatieplatform waar je naar kijkt je in de praktijk besparen? Daarvoor heb je inzicht nodig in hoeveel efficiënter je kan werken met het platform. Maar hoe pak je dat aan?
Als eerste moet je in detail bedenken hoe de toekomstige werkprocessen eruit gaan zien als je datavirtualisatie toepast. Het is een illusie om te denken dat je straks alles kan vervangen door datavirtualisatie. Allereerst moet je je dus een goed beeld vormen van de nabije toekomst:
- Welk deel van de datastromen (in %) kan in de toekomst worden gevirtualiseerd?
- Van de stromen die WEL gevirtualiseerd kunnen worden: wat is de daadwerkelijke besparing die dit op gaat leveren (in %) in termen van TCO.
- Van de stromen die NIET gevirtualiseerd kunnen worden: zijn er deelstappen in die processen waar datavirtualisatie wel hulp en versnelling kan leveren? En zo ja, wat betekent dat voor de besparing op deze stromen (in %) in termen van TCO.
Als je deze analyse hebt gedaan, heb je een genuanceerd beeld over de besparing die het betreffende datavirtualisatieplatform jouw bedrijf kan opleveren. Op het gebied van analyse en ontwikkeling, maar ook op het gebied van onderhoud, beheer, test en acceptatie. Die besparingen kunnen aanzienlijk zien, omdat het proces van ontsluiten van data met datavirtualisatie veel korter en eenvoudiger wordt dan in een traditionele architectuur waar data meerder malen gedupliceerd wordt.
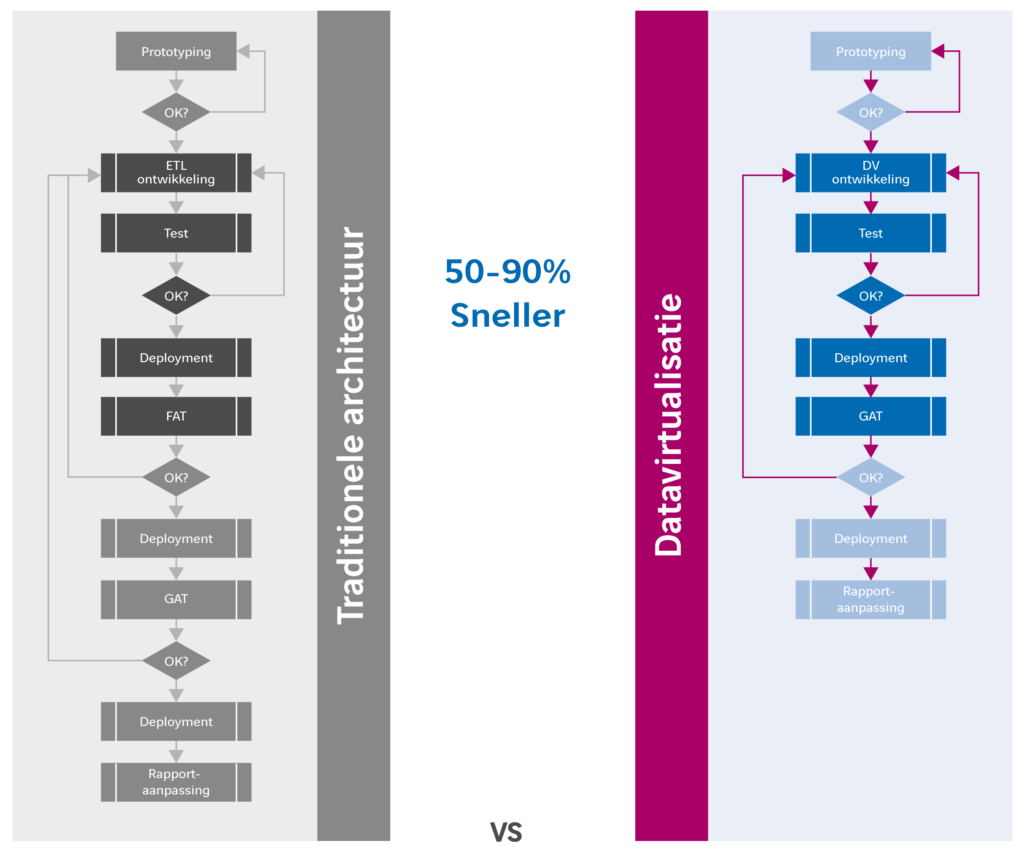 De beste manier om deze analyse uit te voeren is de processen uit te tekenen en de besparingen per processtap te benoemen. Denk realistisch na hoe je in de toekomst gaat werken met het betreffende platform, welke functionaliteiten je gaat gebruiken en welke kennis je daarvoor nodig hebt. Alleen dan kun je een goede inschatting maken over de werkelijke besparing die het platform oplevert. Maak gebruik van best practices of informeer naar ervaringscijfers bij bedrijven die al werken met een datavirtualisatieplatform. Een proof of concept is een bijzonder goede manier om de uitkomsten van je analyse te onderbouwen en verifiëren.
De beste manier om deze analyse uit te voeren is de processen uit te tekenen en de besparingen per processtap te benoemen. Denk realistisch na hoe je in de toekomst gaat werken met het betreffende platform, welke functionaliteiten je gaat gebruiken en welke kennis je daarvoor nodig hebt. Alleen dan kun je een goede inschatting maken over de werkelijke besparing die het platform oplevert. Maak gebruik van best practices of informeer naar ervaringscijfers bij bedrijven die al werken met een datavirtualisatieplatform. Een proof of concept is een bijzonder goede manier om de uitkomsten van je analyse te onderbouwen en verifiëren.
Als het goed is, ga je grote verschillen zien in de mogelijke besparing tussen verschillende platforms. Hoe meer functionaliteit een platform biedt voor jouw specifieke situatie, hoe groter de besparing op je huidige processen. Wat mij betreft speelt ook usability hier een grote rol. Op het moment dat er zeer specialistische kennis nodig is voor het virtualiseren van datastromen is de mogelijke besparing bij voorbaat al veel kleiner. Hoe toegankelijker het platform en hoe uitgebreider de functionaliteit, hoe meer het je kan besparen.
4 – Nieuwe kansen met datavirtualisatie
Vaak valt een business case al positief uit als je alleen naar de mogelijke besparingen kijkt. Dat is mooi, maar het is natuurlijk minstens zo interessant om te kijken naar nieuwe mogelijkheden die ontstaan met datavirtualisatie. Kansen die je nu niet kunt verzilveren, maar wel als je organisatie meer informatie sneller beschikbaar kan hebben. Omdat bepaalde (big) data toegankelijk wordt die je eerder niet kon analyseren. Of omdat je snel externe informatie kan koppelen aan je eigen data. Of misschien alleen al omdat je wijzigingen in je data warehouse kunt doorvoeren in uren in plaats van weken of maanden.
Naar mijn mening ligt hier de grootste winst van datavirtualisatie. Als het veel eenvoudiger wordt om snel nieuwe informatie te ontsluiten, zelf in real time, leidt dat meestal direct tot concurrentievoordeel of zelfs volledig nieuwe business modellen. Een kant en klaar recept is daar niet voor te geven, want die kansen zijn voor elk bedrijf anders. Ik adviseer alleen wel om een business case altijd samen met vertegenwoordigers uit de business op te stellen. Neem de tijd om mensen goed te informeren over het concept datavirtualisitie en om creatief na te denken over mogelijkheden die het biedt. Verken alle kansen en denk out-of-the-box! Bedenk wat een kans je organisatie kan opleveren en kwantificeer dat in euro’s. Als je daarmee klaar bent, heb je alle bouwstenen voor je business case.
Plussen en minnen
Het denkwerk is gedaan en nu is het alleen nog een kwestie van optellen en aftrekken. Dan is de eerste versie van je business case gereed.
In onderstaand voorbeeld heb ik de investering van een ‘medium’ implementatie van een datavirtualisatieplatform (in dit geval Denodo) afgezet tegen een conservatieve schatting van de kosten van een traditioneel data warehouse. Vertaald naar een meerjaren ROI overzicht zie je dat – zelfs met een conservatieve schatting – de investering in het tweede jaar al is terugverdiend. Terwijl het eerste jaar slechts 25% van de besparingen en opbrengsten wordt meegeteld.

Dit voorbeeld is geen uitzondering. In de praktijk blijkt dat organisaties de investeringen in datavirtualisatie vaak op hele korte termijn terugverdienen.
Dit is pas het begin
Je hebt nu een eerste versie van je business case opgesteld, of misschien meerderde versies voor verschillende alternatieven. Dat geeft je de informatie om gericht te kiezen voor één of meerdere platforms die je in een proof of concept (PoC) verder wil onderzoeken. Tijdens zo’n PoC kun je de aannames uit je business case verifiëren en onderbouwen. Op basis van de resultaten van de PoC kun je de business case aanvullen en fine tunen. Daarmee heb je alle informatie voor een goed onderbouwde beslissing om in datavirtualisatie te investeren.
En het is niet klaar na die beslissing. De business case geeft je een middel in handen waarmee je – na de implementatie – het proces kan blijven monitoren en bijsturen, zodat je in de praktijk de beoogde besparingen en opbrengsten kunt realiseren!
Denk er eens goed over na… Welke kansen zou jouw organisatie wél kunnen verzilveren als informatie 10 tot 100 x sneller beschikbaar is voor business gebruikers?